Docentric Toolkit 3.0 is out
ponedeljek, 01. junij 2015
We are pleased to announce a new release of Docentric Toolkit that we were working on for the last several months. While versions 2.X were mostly
addressing PDF and XPS output capabilities, this version makes significant improvements in our template designer - Docentric Toolkit Add-In for MS Word.
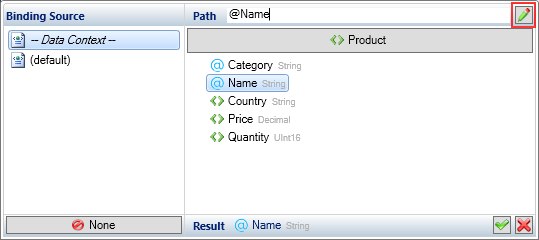
XPath Editor
We have received many complaints about the existing Binding Control in the Add-In for MS Word. Binding Control is handy when a binding path is a simple XPath expression that
can be auto-created by simply picking the correct XML node from the Binding Control. While this is sufficient in most cases, sometimes
more complex XPath expressions are needed to be written manually.
For such cases we have created an XPath Editor that will help you with constructing XPath expressions. There is a new "Edit XPath" button in the Binding Control that brings up
the new XPath Editor.
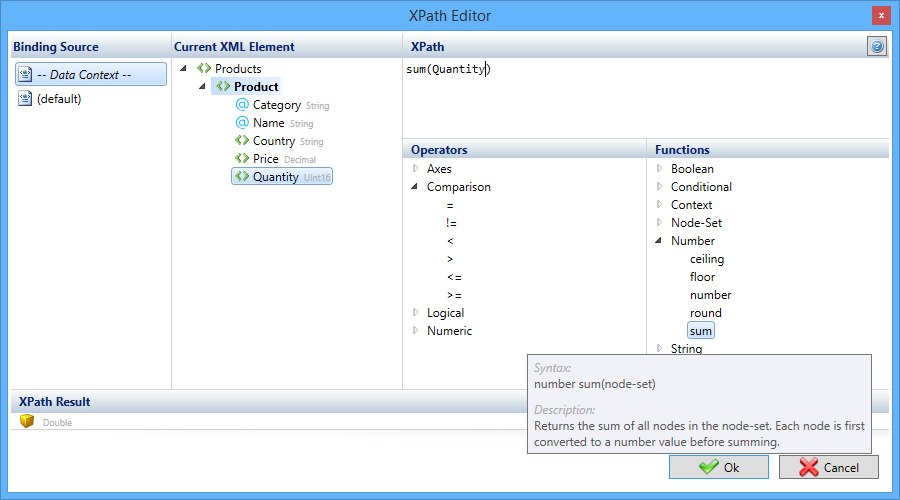
The editor will help you to build XPath expressions by evaluating and validationg them on-the-fly, as you type. The XPath result is shown if the expression is syntactically correct
and valid according to the imported XML schema. Otherwise, a detailed error is displayed.
While building your XPath expression you can use a reference list of XPath functions and operators.
It features built-in help in the form of lists of all functions and operators that you can use in XPath expressions.
Improved XPath support
So far XPath 1.0 has been fully supported and you could write any XPath expression to define an XML data binding. Still, in certain cases XPath was not powerful enough and this
release address these issues.
Limited node selections
Selecting an ancestor of the context XML node was impossible due to the internal working of Docentric Toolkit's data binding mechanisms. For example, you could not use
operators '..', '/' or certain axes. The following XPath expressions, for example, did not work:
../Customer/@Name
/Invoice/Number
This issue has now been fixed and all the operators work as expected.
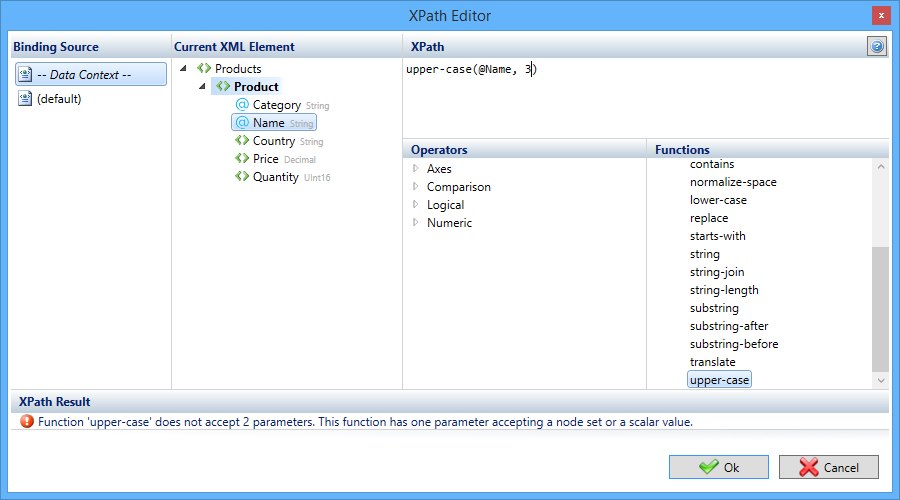
XPath Extensions
XPath by itself is powerful enough to define various calculations, filters and perform basic data shaping. What it lacks are functions. Especially string manipulation functions.
We have completely re-implemented XPath evaluation engine in Docentric Toolkit to address this issue. The new engine is extensible and allows for adding new functions in
addition to the built-in ones as needed. We have already added several functions that you requested or we deemed were missing from the standard set.
The functions that have been added so far are:
iif - Inline IF. Returns the second argument if the first one equals True, otherwise it returns the third argument.current - Returns the current XML node. This is different than the context node. This function always returns the Binding Source XML node.data-source - Returns the root node of the specified data source.-
string-join - Concatenates strings of the give node-set into a single string delimited by the specified character. This function also alows you
to optionally specify a delimiting character for the last string in order to get the result in the following form: String One, String Two and String Three.
lower-case - Lower-cases the given string.upper-case - Upper-cases the given string.replace - Returns a string that is a result of a replacement operation of the specified string by using a regular expression and a replacement string
This is just the initial set of additonal functions. We will be gradually introducing new functions in the future. You are most welcome to tell us what function you are missing
and would like them to be included in the next release.
Selecting related and cross-data-source XML nodes selections
We have been always recommending using highly structured XML documents as data sources. Understanding and dealing with structured XML data from template design perspective
is far more easy as opposed to when having an XML document where all data is in the form of flat XML nodes. Still, sometimes creating structured XML is an overkill or simply
isn't possible.
One example would be a generic document generation system where data is loaded from a database in a generic way. The database contains myriad of different tables and
there is no application that would properly shape the loaded data. The data that comes from the database is always converted to XML first and fed to the document generator,
regardless of the type of the loaded data. Such data will always be unstructured (rectangular) and its corresponding XML will be flat, consisting of XML nodes all being inside the root node.
Consider the following example where a user loads Invoices and their corresponding Items. The corresponding XML might look like this:
...
<Invoice Id="1" .../>
<Invoice Id="2" .../>
<Invoice Id="3" .../>
...
<Item InvoiceId="1" .../>
<Item InvoiceId="2" .../>
<Item InvoiceId="2" .../>
<Item InvoiceId="3" .../>
...
The goal is to create a document with the list of all the invoices where each Invoice row would contain a sub list of its corresponding Items. To achieve this we would need
to place two LIST tagging elements on the template with the first one data bound directly to the data source with the binding path set to Invoice. The LIST
tagging element would this way select only Invoice XML elements. The second LIST element must be nested inside the first one and would represent the second-level list for invoice items.
Since the nested LIST tagging element must select only those items Items that belong to the "current" Invoice, we must data bind it to the "current data context" of the
outr LIST tagging element and set the binding path to an XPath expression that would select only related Items. We could write something like this:
/Items[@InvoiceId = ./@Id]
Well, it turns out that the expression above doesn't work as one would expect. The problem is that the node selector '.' returns the "context" node which in the XPath world doesn't
mean the same as in the data binding world of Docentric Toolkit. Selector '.' inside the filter returns an Item node, instead of the current Invoice node.
Sadly, but XPath doesn't have the means to select the current XML node.
For this reason we introduced our own current() function that always returns the current instead of the context node. So, the proper XPath expression that selects the
Items that belong to a particular Invoice would look like:
/Items[@InvoiceId = current()/@Id]
Preview
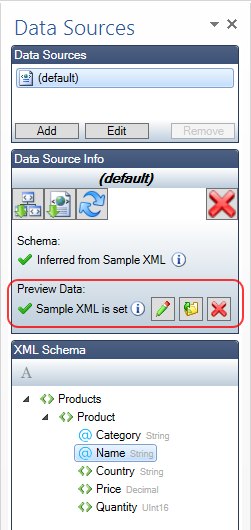
The Add-In for MS Word has finally got the Preview. This function will allow you to generate a document directly from the Add-In.
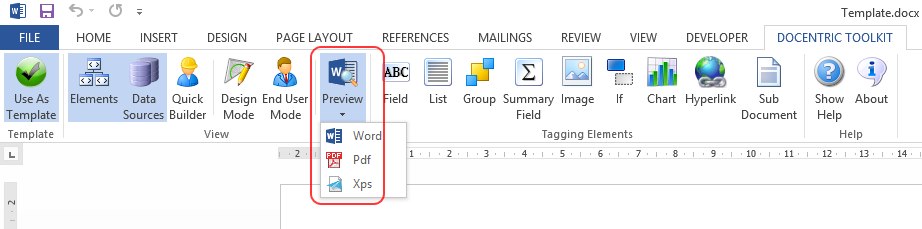
You can now opltionally set sample XML data that is used to populate a template, each time you run the Preview. Note that when you specify an XML to infer the schema from for a data source,
the same XML will be used as a sample XML for previewing.
This functionality is currently available for templates with XML data sources only. We will wait for your feedbacks first before implementing the same for templates with .NET Object data sources.
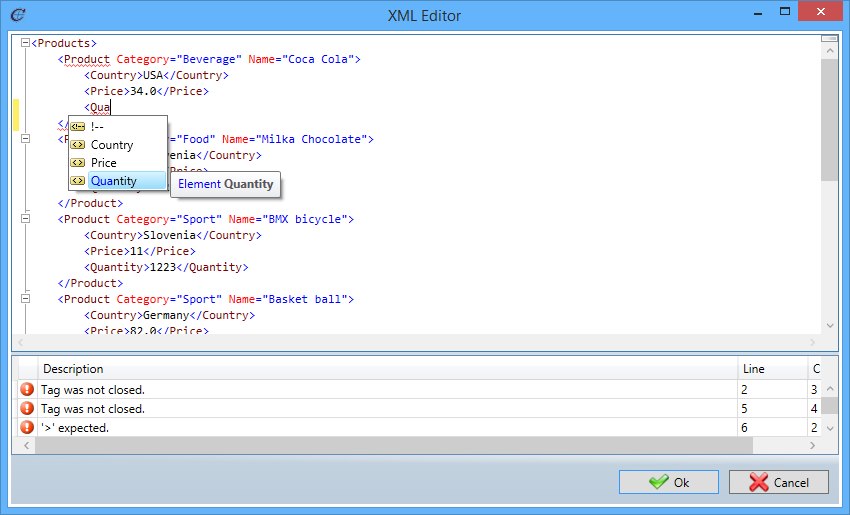
We added another sub-feature. There is a built-in XML editor that you can use to edit a loaded sample XML on-the-fly or creating a new XML document from scratch. If you need to quickly change
the values in a sample XML, you can now simply edit inside thge Add-In, without doing it in an external XML editor and reloading it back in the template.
The new XML editor automatically attaches the schema to the edited XML file. This means that full intellisense and validation will be available as long as the XML schema is specified.
End User Mode
Initially, when we released the first version of Docentric Toolkit years ago we targeted developers with it. But we soon realized that the Add-In was friendly enough for
non-developers that they were using it too. We have been improving user experience for a long time in order to bring the toolkit as close to the template designers (users)
that are not programmers nor they are familliar with software development concepts. Today we know that there are many non-developers designing templates using
Docentric Toolkit Add-In for MS Word.
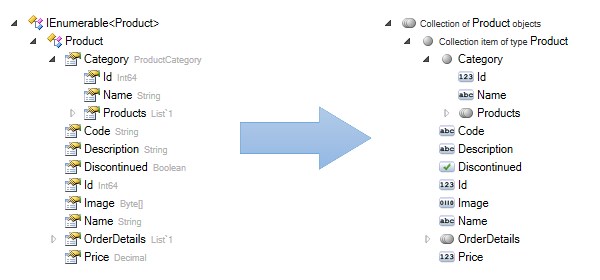
There is a new End User Mode button on the "Docentric Toolkit" MS Word ribbon tab.

It is our latest effort to bring the Add-In even closer to non-developers. This new button
hides some technical details when they are not necessary. It is a toggle button and it affects how schema trees in the Add-In are displayed when using
.NET Object or XML data sources. By turning End User Mode on, views of schema trees change:

Labels
Labels are user friendly names for schema members. When creating an XML schema, you can include labels for each XML element or attribute.
Sometimes XML schemas contain XML nodes with names that are not meaningful enough to a user designing templates. In such cases you can attach labels to XML nodes
which act as descriptions for the nodes. For example, you can add label Request for quotation ID to the attribute RFK_ID.
When labels are present, the Add-In use them in two different ways:
-
A tooltip with the label text appears when a user hovers over the shema tree memebr with mouse cursor.
Docentric Toolkit 2.2 has been released
sreda, 08. april 2015
While this release improves PDF and XPS output even further, it also adds some new important features.
Shapes
Extensive support for shapes (Auto Shapes in MS Word) has been added. Now your (template) documents can also contain shapes such as lines or rectangles, and will be properly saved
to any of the supported output formats. Of course, this is not only true for document generations and conversions. You also have full programmatic
access to shape objects in terms of creation and manipulation.
Form Fields
We added full support for MS Word Form Fields. Form Fields are deprecated since Word 2007 in favor of Content Controls. But we have got quite a lot of requests to add support
for them. It looks like many of you either still deal with a lot of old documents containing Form Fields or there are so many that are simply used to use them instead of the new Content Controls.
Word supports three different Form Fields and Docentric Toolkit Object Model supports them all in the form of three separate classes: TextInput, CheckBox
and DropDown. Since these classes are part of the DOM, you can use them in various document processing scenarios, including extracting or setting
CheckBox.IsChecked values.
PDF/XPS fidelity improvements
We further improved PDF and XPS rendering. This means that the documents that are generated or converted from Word documents to PDF or XPS are rendered with high accuracy compared to PDF documents
saved from within MS Word.
Our PDF/XPS rendering algorithm now also honors several properties that were previously ignored (except when saving to DOCX):
ParagraphFormat.KeepWithNextParagraphFormat.KeepLinesTogetherTableCellFormat.VerticalAlignment
Like always, we are open to suggestions. Try out the new features and let us know what you think. Don't hesitate to tell us if you think you have found missing feature we should implement.
Remember that all of the features that we develop are the result of your feedbacks!
Docentric Toolkit 2.1 has been released
četrtek, 08. januar 2015
This version brings new funnctionality as well as some minor bug fixes and improvements of existing features.
Document Concatenation and combining
We added full programmatic support for combining documents. With the new functionality you will now be able to combine, merge, insert and append documents
in many different ways. The functionality is powerful and flexible enough to implement any document merging scneario that you might think of: from simple document appending to
complex insertions of parts of a source document into a designated point in the target document and all this with being able to control various aspects of the merging process,
such as how styles are merged or where the appended document begins in the target document. You can use document combining functionality through Document.Concatenate,
Document.Append and Document.Import methods.
Document document1 = Document.Load("c:\Test1.docx");
Document document2 = Document.Load("c:\Test2.docx");
Document document3 = Document.Load("c:\Test3.docx");
ImportOptions importOptions = new ImportOptions()
{
ImportStyleMode = ImportStyleMode.CopySourceDocumentStyles,
ImportedDocumentDelimiter = ImportedDocumentDelimiter.SourceDocumentStartingSection,
ImportedDocumentPageNumbering = ImportedDocumentPageNumbering.ForceRestart
};
Document resultingDocument = Document.Concatenate(new[] { document1, document2, document3, document1 }, importOptions);
resultingDocument.Save("c:\Result.pdf");
Much improved PDF/XPS rendering fidelity
A lot of improvements have been done in tearms of rendering fidelity. We added support for many previously unsupported document features and also fixed many misbehaviors.
If you use more advanced features in your documents, such as dynamic fields (TOC), conditional table styles or continuous section breaks, we urge you to migrate to the new version.
Also, if you use DOM (Document Object Model) to convert documents from DOCX to PDF, you will notice that the converted documents look the same for the majority of the input documents.
Saving to DocX now fully supported
Previously, when saving a DOM document via the Document.Save, you were able to choose PDF, XPS or DOCX as the output format. While PDF and XPS formats have been fully supported,
the DOCX support was poor. With the version 2.1 the DOCX format is now fully supported which means that all features that are represented by DOM are properly saved to DOCX.
document.Save("c:\Document1.docx", SaveOptions.Word);
or just
document.Save("c:\Document1.docx");
Docentric Toolkit 2.0 is out!
četrtek, 27. november 2014
Version 2.0 has finally been released. This release brings many new features, most notably PDF output and Document Object Model (DOM).
While PDF output was the main focus while developing version 2.0, DOM has been created as a by-product. Nonetheless, DOM is regarded as the first class feature and
will play a major role in the future of Docentric Toolkit.
New namespaces
Docentric Toollkit 2.0 now has two new namespaces:
-
Docentric.Documents.Reporting
This is in fact just the renamed existing Docentric.Word namespace and represents a minor breaking change. We put all
the existing functionality (of Docentric Toolkit 1.5) inside this namespace. The APIs haven't change much, except for two added GenerateDocument overloads
which accept SaveOptions. You will use them to specify the output format other than .docx.
-
Docentric.Documents.ObjectModel
A completely new namespace containing a completey new set of APIs for programmatic document manipulation.
Fixed Document Output support
As metioned before the major benefit that the new version brings is the PDF format for the generated documents. More precisely, we added the support for Fixed Document
formats and currently PDF and XPS are supported. In the near future we will add other popular formats, such as bitmap formats (png, jpg, bmp, gif).
The Fixed Document rendering produces PDF and XPS documents with high fidelity by converting a Word (template) document first into DOM and then it saves DOM to a selected Fixed Document format.
In its current state it is still not capable of converting all advanced Word constructs/objects such as charts, shapes, OLE objects and some other advanced Word objects.
In the comming months we will mostly be focusing on perfecting the rendering engine and will be gradually adding new features, so you can expect a lot to happen around
PDF/XPS document rendering in the near future.
Document Object Model
DOM is in fact a whole new namespace full of APIs that will allow you to create new or modify existing flow documents, such as Word, using programmatic approach.
It features a lot of classes and methods for document manipulations and you will be able to use them for different document processing tasks:
- Create new or modify existing document.
- Extract specific content from a document, such as images or text.
- Combining and merging multiple documents together.
- Performing Find/Replace.
- Update dynamic fields, such as Table Of Contents (TOC).
The current DOM is a bit limited in terms of constructs and objects found in MS Word. For example, there is not support for charts, some dynamic fields, OLE objects and other
more advanced features found in MS Word. Nonetheless, regarding the supported features, the current DOM APIs closely and accurately model MS Word features and tend to be
as flexible and powerful as possible. Even if a feature isn't supported today, we will most likely implement it in a near future. If you miss a feature, let us know
about it. As always, your requests will most certainly be given high priority on our TODO list.
We encourage you to download the new version, play with it and give us some feedback. We would love to hear what you think about it!
Docentric Toolkit 1.5.3 has been released
petek, 29. avgust 2014
New Features:
- The IMAGE element's 'SizeMode' property has been extended with a new option to choose from: 'Fix Placeholder'. This option instructs the Report Engine to render an image so that it will stretch to the placeholder boundaries while retaining its aspect ratio.
- A namespace Docentric.Word.TemplateManagement has been added. It provides APIs for programmatic creation/manipulation of template documents.
Add-In bug fixes changes:
- MS Word occasionally crashed when closing the application.
Docentric Toolkit 1.5.2 has been released
ponedeljek, 02. junij 2014
Engine changes:
- SubDocument element: If a sub document contains styles with effects and the target document (template) does not, an exception occurred. -> Fixed
Docentric Toolkit 1.5.1 has been released
ponedeljek, 07. april 2014
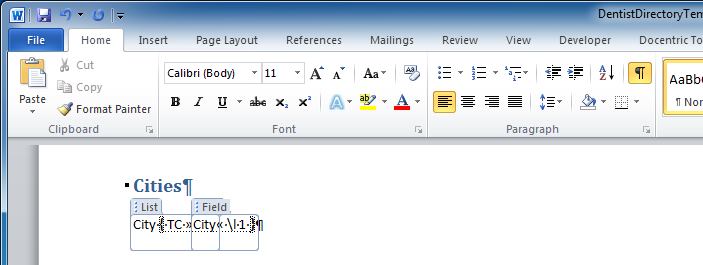
We have added support for tagging Field Codes of MS Word field objects which are a very useful means for building dynamic field like
Table Of Contents, Index, Table Of Authorities, or any other MS Word field object.
For example, you can use a Field tagging element to use it as a placeholder inside a TC field (used to define an index entry) as shown in the figure below:
Docentric Toolkit 1.5.0 has been released
sreda, 12. marec 2014
This release finaly brings the ability to insert HTML into documents, the feature that many of you have been waiting for so long.
It currently supports the basic HTML supported by HTML rich text editors, such as paragraphs, styling tags (bold, italic), tables,
ordered and unordered lists, as well as some of the most important inline styles.
The placeholder tagging element for HTML is not the Field element as some of you would guess but the Sub-Document element. Note that even only a small fragment of HTML
is in Docentric Toolkit considered a document and so the Sub-Document tagging element should be used when designating the document location for an HTML insertion.
Previously, the Sub-Document element always expected only Word document (.docx) as an input value. We have now extended the element by adding the Format property
which can be used to tell the Report Engine what kind of document to expect. Currently there are two values to choose from: Word Document and HTML.
This design will allow us to add support for other document formats in the future, such as RTF.
We added the "Inserting HTML" example to the "Example Browser" application (that installs along with the product) showing this feature in action.
So download the release, play with it and let us now what you think.
If you run on an unsupported HTML feature that you need in your project, please tell us about it.
Docentric Toolkit 1.4.3.23482 has been released
sreda, 19. februar 2014
The SizeMode property has been added to the Image tagging element. It is used to control how the rendered image size is determined.
The default value is Use Placeholder Size.
The original size of rendered images in this size mode gets ignored and the placeholder's size is used. Until now this was the only supported size mode.
The oposite mode is Use Image Size where the image size is used (regardles of the placeholder size) in respect to its DPI. This value mimics MS Word behavior when manual placing (copy/paste)
an image onto a document.
In the Fit Placeholder Width and Fit Placeholder Height size modes an image uses placeholder's width or height while maintaining its aspect ratio.
Docentric Toolkit 1.4.2.23462 has been released
torek, 14. januar 2014
Add-In changes:
- If a SubDocument element is placed into a document header or footer while the corresponding sub-document contains an image, the image is missing (it works fine if placed into a document body). -> Fixed
- When loading a DTS schema from a .NET type containing indexers with multiple parameters an exception occurred. -> Fixed
- When importing/loading a DTS schema it wasn't possible to choose the DTS type usage. -> Fixed
Docentric Toolkit 1.4.2.23456 has been released
sobota, 07. december 2013
Add-In changes:
- When importing schema for a .NET Object data source by loading a .NET assembly from an untrusted source (internet) the Add-In opened an empty "Select .NET Type" window. -> Fixed
- When importing schema for a .NET Object data source by loading a .NET assembly containg a .NET type with no namespace an error occurred. -> Fixed
Docentric Toolkit 1.4.2.23301 has been released
sreda, 13. november 2013
Report Engine changes:
- Chart and SummaryField threw an exception when the 'Value' bindings resulted into 'Null'. -> Fixed
- Image element was throwning an exception when the bound to invalid Base64 string (XML data kind only). -> Fixed
- Using XPath functions that return string resulted in empty outputs (XML data kind only). -> Fixed
Example Browser changes:
- A new example was added that shows how to render collection items each on its own page (OIPP rendering mode).
Docentric Toolkit 1.4.1 has been released
petek, 04. oktober 2013
Report Engine changes:
-
List element One-Item-Per-Page (OIPP) scenario issue: When you wanted each collection item to be rendered
on its a new page there was always a blank line at the beginning of each page (only the first item page was correctly rendered)
and there was always additional blank page (due to the last repeated page break). The engine now always detects an OIPP case and
automatically deletes empty lines and the last page break.
Docentric Toolkit 1.4.0 has been released
petek, 05. julij 2013
-
More flexible licensing model.
The new licensing model featuring the Standard and the Professional edition.
It basically makes a distinction between "document generation" and "reporting". If
you need to produce only documents and tabular reports without charts bound to data
from your application, the Standard edition will suffice.
The new licensing model also introduces new & lower prices, making Docentric Toolkit top
quality yet affordable component.
-
A new data source kind - so called Docentric Type System (DTS).
Docentric Toolkit Add-In for MS Word can also be used by non-technical end users for
the purpose of updating/creating new document templates. DTS is a much simplified .NET
data type system which makes the use of the Add-In easier for business users (e.g.
objects, collections, properties representing data sources have different look and
feel in the Add-In). DTS object can be easily created with the use of a helper function provided
by our side – you can take a look at implementation details in couple of examples
shipped with our demo app Example Browser (installed with
Docentric Toolkit).
-
New feature related to the List Element –
horizontal
rendering
of a collection in a table.
Now you can choose rendering direction of a List element placed in a table row/cell
– so far the List element supported only vertical rendering of table rows.
This feature opened new possibilities and enabled new templating scenarios that were
previously unable to achieve (e.g. a horizontal product catalog).
You can check the examples in the Example Browser to see how
the new feature is used.
Docentric Toolkit 1.3 is out
nedelja, 11. marec 2012
This release adds a very powerful feature to the toolkit. It is called "Sub Document"
element. This is a new tagging element among existing ones in the armoury and it
can be used to insert a document into another one. Basically this element enables
"Document Merging" in the Docentric toolkit but it is not limited just to appending
one document to another. It offers Document Merging in a much more flexible way.
Document Merging in Docentric still follows the template-based Document Generation
approach. Instead of merging two documents into a third one you create a template
and place Sub Document elements each representing a sub document. When generating
the final document each sub document will be inserted in the place of the corresponding
Sub Document element in the template. This way you can also insert sub document
into table cell of another document or use this functionality to achieve recursive
results (insert the first document into the second one and then the second one into
a third one ...).
Also a very important addition to the toolkit is the "Example Browser" application
which gets automatically installed with the setup. Like its name implies it is an
application containing various examples showing important features of the toolkit.
It is also a good learning source because the source code of the application is
also available.
You can get the new version from our download page.
Docentric Toolkit 1.2 has been released
nedelja, 13. november 2011
This version adds support for so called "Multi-Pass Document Generation". The feature
allows you to render a document in more than just one pass. Until now, at report
generation time all Docentric elements were always processed and merged with data.
The output document was "Finalized" which means that such a document didn't contain
any Docentric elements; it was a plain .docx document.
From now on you can generate documents in more than one step (pass) by doing the
following before calling the 'GenerateDocument' method:
- instruct the report engine not to finalize the output document
- specify elements that need to be excluded from the generation process.
A non-finalized output document is still a report template (containing some of the
elements that were excluded from processing) which can be used as an input into
another document generation (another pass).
Docentric Toolkit 1.1 has been released
sreda, 28. september 2011
Support for XML data source, new Docentric Element Summary Field,
new Docentric Add-In smart tool Quick Builder and much more. Please take
a tour with our Overview Video.
Docentric is Bleeding Edge 2011 Conference Sponsor
torek, 20. september 2011
Bleeding Edge 2011 will take place
from 29th till 30th September 2011 at Špik Congress Centre, Gozd Martuljek, Slovenia.
Docentric is going to be there as one of the sponsors. At the conference we are
giving away 3 Docentric Toolkit Licenses for free!
Docentric 1.0 has been released
ponedeljek, 30. maj 2011
Version 1.0 finally released. Come and see the Docentric Toolkit in action!
